| インデックスのロード操作 |
プログラムから検索処理を行う前に、検索対象となるインデックスを共有メモリにロードする作業が必要になります。インデックスのロード方法はオペレーションガイドの 「開発関連ツールの使い方 − msctrl − インデックスのロード方法」 にて解説されているので参照してください。
ロードはサーバーの再起動やMindSearchのデーモンを立ち上げ直した場合にも再度実行する必要があります。また、そのインデックスを再作成した場合にも必要です。(インデックスの再作成のみ行い、ロードをせずに検索に入ると同期異常のエラーを検出します)
なお、API経由でloaderと通信することで直接インデックスのロード処理を行う ことも可能です。
| 検索パスの指定 |
検索コマンドを発行する前に「検索パス設定」コマンドにより検索対象となるインデックスのパスを指定します。但し、ここで指定するパスは実パスではなく、共有メモリにロードした時のシンボル名(検索パスシンボル)です。
検索パス設定
(形式)
CMD:インデックスを{つかい|使い}"SYMBOL"を検索パス設定
- 「インデックスをつかい」,「インデックスを使い」のどちらも可
- SYMBOL: ロードした時の検索パスシンボル
(レスポンス)
OK:#n
n: 認識したインデックスパスの数
(レスポンスの例)
OK:#1
操作例/API例
(操作) (loaderとのAPIでも可)
$ msctrl load @symeiga sample/indexes/eiga
(API)
CMD:インデックスをつかい"symeiga"を検索パス設定
OK:#1
検索パス設定コマンドはインデックス作成時でも使われるものです。両者を区別するため検索時には「インデックスをつかい(使い)」の前置詞が付きます。パスのクオーティングには "SYMBOL" 以外に、[SYMBOL] なども使えます。詳しくはインデックス作成時での検索パス指定の解説を参照してクタさい。
複数のインデックスを横断検索する場合、ロード時に複数のインデックスを一つの検索パスシンボルに対応させることで行い、検索時は常に1つの検索パスシンボルの指定となるので注意してください。
| 「検索」コマンド |
検索は以下のように複数のコマンドを組み合わせて実行および結果の取得をおこないます。
----------------------------------------------------------------------------------------
(形式)
KEY:<キーワード群>
CMD:検索
GET
GET
...
GET
<キーワード群> := "キーワード"{and|or}"キーワード"{and|or}・・
(1) KEY:<キーワード群>
(2) CMD:検索
左右端の空白は削除されます。内部にある空白については、半角・全角を問わず連続した空白は1個の全角空白に正規化されます。
正規化の指定その他のモードの解説については、正規化の詳細と各種動作モード をお読みください。
文法は「検索」コマンドの前段で使われる"KEY:"と同じです。キーワード群を抽出し、正規化し、AND/OR関係を付け、解析結果をレスポンスとして返してきます。この様子をコンソールから眺めると、MindSearchがキーワードをどのようにして正規化しているのか分かる・・とういものです。
いきなり検索コマンドにかけてしまうと、外からはMindSearchの内部処理が見えないことから、「なぜこのキーワードでヒットしないのだろう」と悩んでしまうことがあります。そのようなときに本コマンドで正規化結果を直接確認すれば解決に役立ちます。
----------------------------------------------------------------------------------------
(形式)
CHK:<キーワード群>
映画 監督
↓
"映画"and"監督"
のように、MindSearchが受け入れるフォーマットに組み立てる必要があります。Perl, Java, PHPで開発しているのであれば、sample/program/perlCGI/ または javaCGI/ に入っている簡易検索サイトのプログラム、あるいは sample/program/phplib/ に入っているライブラリを参考にしてください。この処理をおこなっているのは以下のソースコードです。
(キーワードを整形処理する関数を含むソースファイル)
Perl: formatKeywords.pl
Java: FormatKeywords.java
PHP: msch_format_keywords.php
MindSearchの仕様として、OR優先であることや、たとえば括弧囲みによるグルーピングはできないこと・・などの制約があります。必要であれば検索画面の中で、あるいはそこから誘導する解説画面の中でルールを説明するようにしてください。次いで「GET」コマンドを実行すると検索結果が得られます。このとき、すべての検索結果が一気に返されるわけではないことに注意してください。1つの検索結果の断片が返され、それに対してアプリケーションが「GET」を送信すると、ふたたびMindSearchに制御が移り、次の検索結果の断片が到着する・・というキャッチボールになっています。どちらか一方の側が二度続けてデータを送出することはありません。
送受信されるデータをすべて眺めると次のような応酬となっています。
Send=KEY:"監督"and"センス"
Recv=OK:
Send=CMD:検索
Recv=OK:1件(精密) 1件(ラフ) 0分0秒301ミリを消費
Send=GET
Recv=SS:1|XFL|eiga/eiga1.txt|20031216010201||||1|1
Send=GET
Recv=SB: 1.ふたりのベロニカ 片桐 真喜子
Recv=SB: 私は、この映画の
Send=GET
Recv=SR:監督
Send=GET
Recv=SB:クシシュトフ・キェシロフスキは何という
Send=GET
Recv=SR:センス
Send=GET
Recv=SB:の持ち主だろ
うと、今でも驚いている。
Send=GET
Recv=ES:3
通常は コマンドの実行は「OK:」あるいは「NG:」レスポンスが返されることで完了する のですが、検索コマンドの実行では例外として、「ES:」レスポンスをコマンド実行の弱い終りとみなすことができます。たとえばこのタイミングで「CAN」を送信することでコマンドを中止できます。または「SUS」を送信することで作業終了することができます。直ちに「OK:」が返され、次のコマンドを実行できるようになります。 (ファイルの場合)
SS:A|B|C|D|E|F|G|H|I
A ヒット番号(1から始まる)
B "XFL"固定 (X=indeX FL=File)
C ファイル名(パス部は検索ベースパスからの相対)
D ソートキー(ファイルの場合は常に日時(14桁の数字))
E (不使用)
F オリジナルファイルのベースパス
G 上位URL (「上位URL出力」がオンの場合のみ,オフなら空文字)
H 総ヒット数(検索結果取得可能な範囲で制限)
I 総ヒット数(無制限)
(データーベース検索の場合)
SS:A|B|C|D|E|F|G|H|I|J|K|L|M
A ヒット番号(1から始まる)
B "XDB"固定 (X=indeX DB=DataBase)
C データーベース名
D プライマリキー
E レコードID
F ソートキー(ソートキー#1〜#9のうち検索時指定したもの)
G 主副index識別("main"または"sub")
H 総ヒット数(検索結果取得可能な範囲で制限)
I 総ヒット数(無制限)
以下はレスポンスの例です。
(ファイル検索の場合)
SS:1|XFL|tokkyo/tok10.txt|19901227121300||||5|5
(データーベース検索の場合)
SS:1|XDB|tokkyoDB|tok10|sub10|19901227121300|sub|5|5
SB: 私は、この映画の
SR:監督
SB:クシシュトフ・キェシロフスキは何という
SR:センス
SB:の持ち主だろ
うと、今でも驚いている。
アプリケーションにおけるこのレスポンスへの処理は比較的容易です。SB:レスポンスのデータ部は(たとえば)黒い色で表示し、SR:レスポンスのデータ部は(たとえば)赤い字で表示するといったことをおこなえば済みます。前記例ですと次のような表示をブラウザに対しておこなうことになります。(CGIの出力)
|
私は、この映画の<font color="red">監督</font>クシシュトフ・キェシロフスキは何という<font color="red">センス</font>の持ち主だろ うと、今でも驚いている。 |
(ブラウザの表示)
|
私は、この映画の監督クシシュトフ・キェシロフスキは何というセンスの持ち主だろ うと、今でも驚いている。 |
改行コードはSB:/SR:レスポンス中に「ありのまま」含まれています。先の例では、
SB:の持ち主だろ
うと、今でも驚いている。
の部分がそれに相当します。「持ち主だろ」の直後に改行が有り、「うと、今でも驚いている。」と続き、これがひとかたまりのSB:レスポンスです。このようなことから1レスポンスが1行だと思わないでください。原文相当で複数行分のレスポンスが1つのSB:で返されることもあります。逆に、原文相当では行中のほんの数文字が1つのSB:で返されることもあります(これはSR:のほうが可能性が高いでしょう)。
HTML組みで出力する場合には、どのみちHTMLデータ中の改行は無視されのであまり気にしなくて良いですが、たとえばクライアントマシン上にウィンドウ表示するなど、改行コードが意味を持つような表示を行なう場合には注意が必要です。
アプリケーションはES:レスポンスを受信した直後、「GET」の代わりに「CAN」を送信すると受け取り(GETの動作モード)を中止できます。MindSearchコアから「OK:」が返され、新しいコマンドを送信できるようになります。
さらには、ES:3(1件のヒット情報の最後)の直後では「SUS」コマンドをMindSearchに送ることで「一旦終了」させることもできます。たとえばブラウザへ10件表示し終わったタイミングなどで使われます。(通常のコマンド待ちでも「CAN」送出は可能です)
よく誤解されることですが、MindSearchは「1画面に何件のヒット情報を表示するか」という管理機能はまったく持っていません。それはアプリケーションが主導権を持っておこなうことです。10件ずつ得たいのならそのように出来ますし、逆に1000件のヒットがありアプリケーションから延々と「GET」を投げるのであれば、最後の1000件目まですべてのヒット情報を一気に受け取ることも可能です。
またページ遷移についても同様です。任意場所へのシークとGETの仕組みは用意されているので容易に実現可能ですが、MindSearchがページ遷移全体を管理するわけではありません。やはりアプリケーションの仕事となります。
テキストファイル‥特にHTML‥ではそのタイトル(<title>〜</title>の間のテキスト)を別に扱えると便利です。
(形式)
CMD:タイトル出力をオン
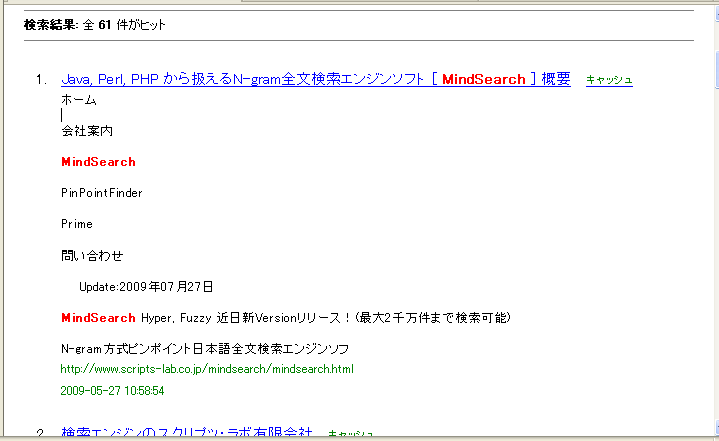
上のコマンドを検索コマンドの前に実行しておくことで、ヒットしたテキストのタイトル部を分離して返すようになります。次のようなレスポンスが返されます。|
GET SS:1|XFL|www.scripts-lab.co.jp/mindsearch/mindsearch.html|20090527105854||| | SSレスポンス | ||
|
GET SB:Java, Perl, PHP から扱えるN-gram全文検索エンジンソフト [ GET SR:MindSearch GET SB: ] 概要 GET ES:1 ←ES:1はタイトルの終わりを意味する | タイトル | ||
|
GET SB:ホーム 会社案内 GET SR:MindSearch GET SB: PinPointFinder Prime 問い合わせ Update:2009年07月27日 GET SR:MindSearch GET SB: Hyper, Fuzzy 近日新Versionリリース!(最大2千万件まで検索可能) N-gram方式ピンポイント日本語全文検索エンジンソフ GET ES:3 ←ES:3は1件のヒット情報の終わりを意味する | ボディ | ||
|
GET OK: | (次のヒットのGET) |
上記のように、SS:のあと、まずタイトルの情報と ES:1 が返されます。さらに GETを送出することでボディ部と ES:3 が返されます。
sample/program/perlCGI/ または javaCGI/ に入っている簡易検索サイトのプログラムが上記処理をおこなっているのでコードを参考にしてください。(検索対象に「Web」を選んだ場合に CMD:タイトル出力をオン しています)
| ソート指定 |
本機能は主にデータベースモードで作成したインデックスの検索に使いますが、ファイルからのインデックスであっても、強制的にソートキー1に日時(ファイルのタイムスタンプ)が登録されているため、これを使ったソートは可能です。検索結果は必ず何らかのキーによりソートされます。デフォルトではソートキー1(多くの場合日時)の降順です。
ファイル検索でもデフォルトのソートキー1(タイムスタンプ)の降順がデフォルトであり、これが唯一のソートキーとなります。
ソート方法は以下のコマンドで指定することができます。「検索」コマンド発行前であればいつでも構いませんが、ソート方法を変更した場合には再度「検索」コマンドを発行する必要があります。
(形式)
CMD:nを{昇順|降順}でソート指定 ←nは1から9までの数字(ファイルからの検索では1のみ指定可)
(スクリプト例)
CMD:2を昇順でソート指定
(デフォルト)
CMD:1を降順でソート指定 ←デフォルトはソートキー1の降順
ソートキータイプの指定は有っても無くても構いません。指定が有った場合、インデックス作成時のソートキータイプ列と先頭部が合致している必要があります。(インデックス作成時より短いタイプ列を指定することは構いませんが長い場合はエラーとなります)| 絞り込み検索 |
本機能は主にデータベースモードで作成したインデックスの検索に使いますが、ファイルからのインデックスであっても、強制的に絞り込みキー1に日付が記入されているため、これを使った絞込み検索は可能です。通常はドキュメント本体の中に指定キーワードを含むものがヒットとなりますが、絞り込み検索を併用すると、インデックス作成時に各レコードに対して別途指定した絞り込みキーも合わせて合致を検査するようになります。
KEYコマンド発行の前に 絞り込みキータイプの指定 が必要です。絞り込みキータイプの設定方法はインデックス作成のそれと同じになります。(ファイルからのインデックスで日付絞り込みを行う場合は、「R」を指定してください)絞り込みキーの指定は KEY: コマンドによるキーワードの指定の中で行ないます。
インデックス作成時に指定した絞り込みキータイプと同じものを検索時に指定しますが、検索時はインデックス作成時よりより短いキータイプ列(実際に使う部分のみ)を指定しても構いません。この仕様は複数インデックスの横断検索時、共通する最小長を指定するのにも役立ちます。
(形式)
CMD:「<タイプ列>」を絞り込みキータイプ設定 ←インデックス作成時と同じものを指定
KEY:N"絞り込みキー"and<キーワード群>
CMD:検索
(スクリプト例1)
CMD:「RSSS」を絞り込みキータイプ設定
KEY:1"20080101-20091231"and"映画" ←絞り込みキータイプ'R'の場合は範囲指定可
CMD:検索
(スクリプト例2)
CMD:「RSSS」を絞り込みキータイプ設定
KEY:1"20080101-20091231"and2"PA68301"and"映画" ←二つの絞込みキーを指定
CMD:検索
前記のように、文法上は複数語のAND結合であるかのように指定します。上記例2では 絞り込みキー1(日付想定)が2008年〜2009年であり、絞り込みキー2 が PA68301 に合致し、かつ「映画」をテキスト部に含むレコードのみをヒットとするような検索がおこなわれます。インデックス作成時、データーベースモードで ソートキー1→絞り込みキー1 への日付転写を行わせる方法については こちら を参照してください。
| 代替絞り込みキーを使う検索 |
テキスト本体の中に(データーベースのように)絞り込みキー情報を埋め込み、検索時にそれを指定することで、絞り込みを使った検索を行わせることができます。
本来はデーターベースモードでの検索機能強化目的で設置されたものですがファイルからの作成でも使うことができます。
インデックス作成時の事項は インデックス作成コマンド(データーベースから作成)−[代替絞り込みキーについて] を参照しください。
注: 代替絞り込みキーを使うことの宣言はインデックス作成時に必要なだけで、検索時には必要ありません
サンプルテキスト群の一つに、sample/texts/eigaAltKey/ というフォルダがありますが、これは代替絞り込みキーのテストのために置かれているものです。この中の一つ eiga2.txt の先頭部は次のようになっています。
----------------------------------------------------------------
_AREA_大阪_ _SIZE_M_ _AT1_ABD_ _AT2_ABCE_ _AT3_DEG2_
空白で区切った複数のトークンが記述されていますが、一つ一つのトークンが属性名と属性値のペアとなります。このうち一つを検索時に(普通のキーワードのように)指定することで絞り込みを行わせることができます。
最初の一つが「_AREA_大阪_」ですが、AREA が絞り込みキーの属性名、大阪 がその値に相当します。
属性名、属性値とも表記や長さは自由ですが、左右端は必ず記号 '_' が置かれるようにしてください。
検索時には次のようなキーワード指定を行います。
↓代替絞り込みキー
KEY:"_AREA_大阪_"and"ポーランド"
↑通常のキーワード指定
ちなみに、
KEY:"大阪"
のように、通常キーワード形式で代替絞り込みキー列を狙った検索をおこなった場合にはヒットしない仕組みになっています。インデックス作成時におこなった CMD:代替絞り込み使用をオン はこの効果をもたらすものです。代替絞り込みキーワードは専用の絞り込みキーとは違って正規化の対象となるため、半角・全角、小文字・大文字は同一視されます。(通常のキーワードと同じ扱いです)
| その他の機能 |
このコマンドは一度、検索コマンドを使って何かヒットしたことを確認した後に使うことができます。(何もヒットしないドキュメントを得ることはできません)。
----------------------------------------------------------------------------------------
(形式)
GET:n+ (nはヒット番号)
大きなドキュメントではSB:レスポンスは複数に分けられることもあります。「OK:」あるいは「NG:」が返されるまでは繰り返し「GET」を発行するようループを組んでください。
| 検索結果のシークとGET |
「検索」コマンドが「OK:」のレスポンスで終了した後には好きなタイミングで検索結果の任意の場所にシークしたり結果を取り出すことができます。さらには、「SUS」コマンドでアプリケーションを一旦終了したあと、再度アプリケーションを起動し、「RES」コマンドにより作業再開した後にもシークや取り出しをおこなうことができます。
注:ここで述べる内容は、セッション管理 と密接に関係があります。そちらの解説も合わせてお読みください
- 「検索」コマンドが「OK:」レスポンスで終了した後、新しいコマンドを送信できる任意のタイミング
- 「GET」コマンドを送出して検索結果が返され、「ES:3」レスポンスを受信した直後
(検索結果の読み出し単位も合わせてお読みください)- 「RES」コマンドにより作業再開した後、コマンドを送信できる任意のタイミング
- GET:?
- ヒット件数を調べます。以下のレスポンスが返されます。
OK:n,m
n:総ヒット数(検索結果取得可能な範囲で制限)
m:総ヒット数(無制限)
- GET:n
- n件目の検索結果位置にシークすると同時に検索結果の取り出しを行ないます。
レスポンスとして以下のいずれかが返されます。
(1) SS:<--センテンス情報--> n件目の検索結果の返送が始まる
==SB:, SR: .. ES:3 までのレスポンス(その都度、GET送出のこと)==
(2) OK: この番号のヒットセンテンスが存在しないとき
- GET:n+
- n件目の検索結果位置にシークすると同時にn番目のドキュメント内容全文を(サマリではなくすべてを)取り出します。詳しくは「全文取得」の項を合わせてお読みください。
注:GETコマンドを一つ実行するごとに「次の取り出し位置」が進みますが、この情報はコネクションが切れた場合は(SUS/RESコマンドで情報再現した場合でも)維持されないため、取り出し位置はアプリケーションで管理してください。