| 正規化 |
フィルタ(プレーンテキスト化)
フィルタを適用する/しない、適用するとしたらどのフィルタ・プログラムを使うかは、フィルタ定義ファイル で規定されます。
文の切り出し
(原文の例) ――――――――――――――――――――――――――――――――――――――― □□□□今度の「ふたりのベロニカ」はそれらとはまったく違った、優しく幻<cr/lf> □□□想的なファンタジーなのである。体制が激変したことと決して無関係で<cr/lf> □□□はないという、この一つの芸術作品を私は讃えずにはいられない。<cr/lf> ―――――――――――――――――――――――――――――――――――――――注:原文通りではなく、説明のためにわざと組替えています
上の文章は2文から成っています。各行頭は字下げがおこなわれ、なおかつ語の途中で改行が入っています(「幻想的」は「幻」と「想的」に分断されています)。メールではこのようにな体裁はよく見かけます。
MindSearchはまずこのような原文から、行頭の字下げや改行コードを一旦取り払い、1本につながった「文」を切り出します。切り出された文は次のようなものです。
[原文1]
今度の「ふたりのベロニカ」はそれらとはまったく違った、優しく幻想的なファンタジーなのである。
[原文2]
体制が激変したことと決して無関係ではないという、この一つの芸術作品を私は讃えずにはいられない。
文字の正規化
[正規化文1]
今度の ふたりのベロニカはそれらとはまったく違った 優しく幻想的なフアンタジイなのである。
[正規化文2]
体制が激変したことと決して無関係ではないという この一つの芸術作品を私は讃えずにはいられない。
文1の末尾にを見ると元の語の「ファンタジー」が変化しています。正規化はたとえば「方言を標準語に直す」ようなものではなく、一見すると変な表記に揃えることもあります。目的はあくまで原文とキーワードとの間のパターンマッチングであるため、正規化文が原文から乖離することは問題にはなりません (キーワードもまた正規化されるので)。キーワードの正規化
MindSearchは、検索者が入力したキーワードもまた「正規化」します。たとえば、キーワードが「幻想」と「ファンタジー」だとすると次のように正規化されます。
[キーワードA] 幻想
[キーワードB] フアンタジイ
(厳密には原文の正規化とキーワードの正規化はわずかに違いがありますすが(特にカタカナ)、ここではあえて触れません。おおむね同じ正規化がおこなわれます)
| 検索 |
パターンマッチング
MindSearchは原文の各文が正規化されたものの中に、キーワードを正規化したパターンが含まれるかどうかを検索します。
マッチングの様子を細かく追うと以下のようになります。まず、正規化された原文に正規化済みキーワードを含む部分を見つけます。
[正規化文1]
今度の ふたりのベロニカはそれらとはまったく違った 優しく幻想的なフアンタジイなのである。
赤がヒット箇所です。次に正規化文のこのヒット文字位置から原文での文字位置を割り出し(そのような情報を管理しています)原文におけるヒット箇所にマッピングします。その結果、
[ヒット文出力]
今度の「ふたりのベロニカ」はそれらとはまったく違った、優しく幻想的なファンタジーなのである。
という把握がおこなえます。
SS:1|XFL|eiga/eiga2.txt|20031215010202||||1|1
SB: 政治的に大きな変動のあったポーランドは、まだ訪れたことのない地だが、全体を
SR:セピア
SB:のクラシカルな
SR:色調
SB:の中で描き、はかなさと淡い期待を、隅々まで静謐に含んだ映像が新鮮だ。
〜略〜
ES:
OK:
上記がMindSearchからアプリケーションへ検索結果として返される情報です。まず最初に、
SS:1|XFL|eiga/eiga2.txt|20031215010202||||1|1
いうレスポンスが返されます(これだけで1レスポンスです)。次の、
SB: 政治的に大きな変動のあったポーランドは、まだ訪れたことのない地だが、全体を
SR:セピア
SB:のクラシカルな
SR:色調
SB:の中で描き、はかなさと淡い期待を、隅々まで静謐に含んだ映像が新鮮だ。
〜略〜
ES:
はヒット文(サマリ)の内容です。一度に返されるわけではなく複数のレスポンスに分かれています。通常ではヒットキーワードを強調表示することがよくあり、その便宜のため、「通常文字」部分と「強調文字」部分に分けて返しています。ES:は「End of Sentense」の略で、1件の検索結果の終りを示します。
このような情報を元にアプリケーションは画面への出力をおこない最終的にたとえば次のような画面となって閲覧者に表示されることになります。
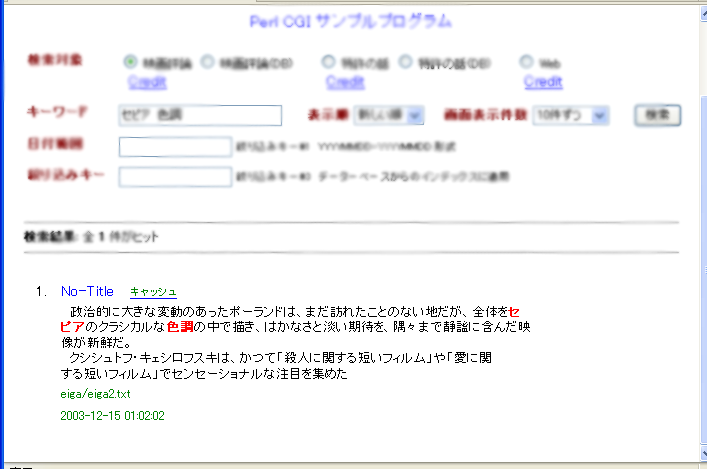
MindSearchから返される情報はプリミティブな情報であり、HTMLで組まれたヒット情報が返されるわけではありません。もしWebアプリケーションとして実現するのであれば、HTMLタグで情報を囲んだり、色を付けたりする、いわゆるプレゼンテーション・レイヤの部分はアプリケーション側(開発者)の役割になります。